

















AI's landscape has dramatically shifted with the advent of large language models (LLMs), which stand at the forefront of today's natural language processing (NLP) breakthroughs. These sophisticated models are adept at generating text that remarkably resembles human writing, covering a broad spectrum of areas. There's a growing movement towards customizing LLMs for particular industries – picture, for instance, chatbots designed specifically for legal professionals or those dedicated to healthcare experts.
In this blog, I'll guide you through the significant benefits of domain-specific LLMs. We'll explore three essential strategies for tailoring these models: prompt engineering, retrieval augmented generation (RAG), and fine-tuning. To make these concepts more tangible, I'll introduce an approach I like to call the "student analogy." Let's get started!
Key benefits of customized LLMs
Tailoring LLMs to your specific domain has the following benefits:
-
Precision and Insight: By focussing on datasets specific to areas such as law or healthcare, LLMs achieve not only higher accuracy but also a deep understanding of industry-specific nuances, outperforming general models in relevance and detail.
-
Consistency and Dependability: Focusing on a particular field reduces the models' exposure to irrelevant data, leading to outputs that are more consistent and trustworthy.
-
Risk Mitigation: In high-stakes domains like healthcare and law, inaccuracies can have serious consequences. Domain-specific LLMs, enhanced with extra safety features, provide safer, more reliable insights.
-
Enhanced Interaction: Interfacing with an LLM that understands and utilizes the specific terminology and context of a domain results in a more satisfying and effective user experience.
-
Efficiency in Operation: It's often more resource-effective to fine-tune a smaller, domain-specific model than to operate a large, general-purpose one. These specialized models can deliver superior results more cost-effectively.
In conclusion, while versatile general-purpose LLMs can tackle a variety of tasks, domain-customized LLMs are tailored to meet the specific requirements and complexities of individual fields, resulting in outputs that are more precise, dependable, and effective. They serve as a vital link between broad knowledge and specialized expertise, enhancing the overall performance and relevance of the models.
Customizing LLMs for domain precision
Having highlighted the importance of domain-specific LLMs, let's now explore a comprehensive three-step guide to creating specialized LLMs. The following section will delve deeper into these techniques, providing a detailed discussion of each step.

Prompt engineering, RAG, and fine-tuning can offer a three-step approach for building domain-specific LLMs.
Step 1: Prompt engineering
Utilizing prompt engineering is a swift method to extract domain-specific insights from a generic LLM without altering its structure or requiring retraining. This technique involves formulating targeted questions or prompts to direct the model in generating outputs tailored to a particular domain. For example, instructing a general model to "Always provide concise answers using medical terminology" prompts it to deliver brief, medically-focused responses. For further guidance on crafting effective prompts, consult the “Introduction to prompt design” documentation guide for insights on eliciting desired responses from language models available through Vertex AI on Google Cloud.
Step 2: RAG (retrieval augmented generation)
RAG leverages the power of combining information retrieval with LLMs. By linking to external knowledge sources like a database of documents, the LLM can access relevant information to craft its responses. This functionality is crucial for delivering transparent and precise answers, enabling the model to tap into real-time or specialized data that may surpass its initial training set. For example, when designing a medical chatbot, RAG empowers the LLM to tap into a repository of current medical literature, research papers, and clinical guidelines. Consequently, when a user seeks information on the latest treatment for a specific condition, the LLM can draw upon the most recent data from this database to offer a comprehensive response rooted in the latest medical advancements.
Google’s Vertex AI Search provides a complete RAG search pipeline, allowing users to create AI-driven search experiences for both public and internal platforms. Additionally, Vertex AI Vector Search, previously known as the Vertex AI Matching Engine, offers a vector database seamlessly integrated with your LLM, facilitating the development of RAG-driven question-answering chatbots, as detailed in this article.
It's important to note that while constructing a RAG prototype may seem straightforward, building a production-level RAG system involves significant complexity. This process often demands continuous quality enhancements and necessitates making intricate design choices, such as selecting suitable embeddings, determining the optimal vector database, and identifying the most effective chunking algorithms.
For those seeking a deeper understanding of RAG technology, I recommend delving into the insights shared in the Medium article titled "Advanced RAG Techniques: an Illustrated Overview," and exploring the detailed discussions in this Google Cloud blog post "Your RAGs powered by Google Search technology." These resources shed light on the intricacies and crucial design decisions essential for developing advanced RAG systems.
Step 3: Fine-tuning
Specializing a pre-trained LLM like PaLM 2 for Text (text-bison) on Vertex AI involves fine-tuning the model with a smaller, domain-specific dataset. This process enhances the model's proficiency in that particular area, such as refining its understanding of medical topics when equipped with RAG for medical knowledge. By incorporating relevant medical insights from RAG and refining responses with appropriate terminology and phrasing through fine-tuning, the model can deliver more precise and informative answers.
For further guidance on tuning language foundational models on Vertex AI, refer to the provided resources for detailed instructions. Remember, while the suggested sequence of these approaches offers a structured way to tailor LLMs, feel free to adapt and combine these techniques based on your project's requirements. Each method can be utilized independently or in conjunction with others, allowing flexibility in optimizing your model's performance. Explore the following section for an in-depth comparison of these strategies.
Comparing prompt engineering, RAG, and fine-tuning
Below is a comprehensive comparison showcasing the distinct advantages of prompt engineering, RAG, and fine-tuning in the context of customizing language models.
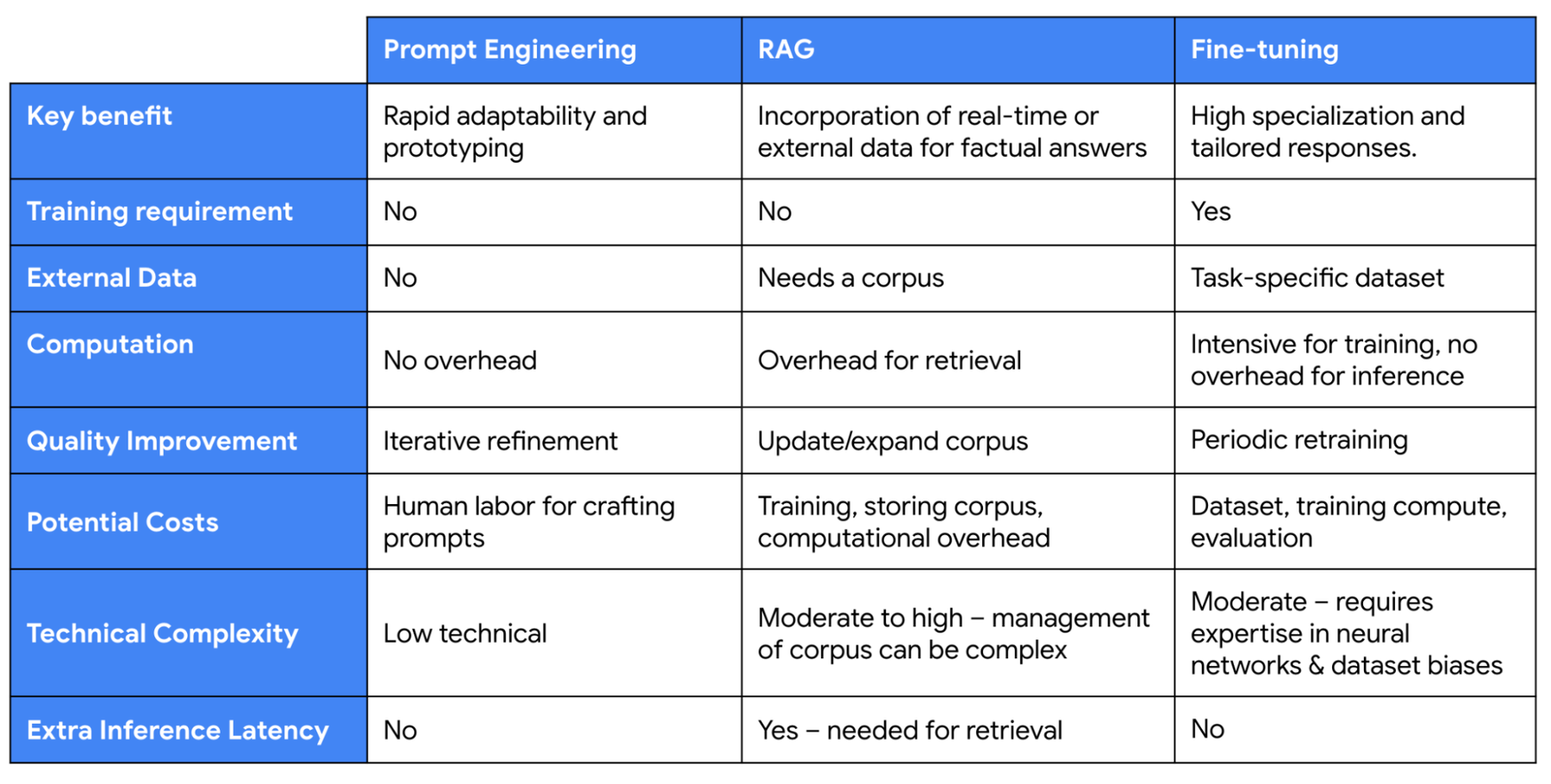
Comparison of prompt engineering, RAG, and fine-tuning
Imagine the concept of prompt engineering, RAG, and fine-tuning as a journey for a student eager to master a new language. Picture the LLM as the student, starting from scratch in a vast library of language resources. This immersion helps them grasp the basics but might leave gaps in specialized knowledge.
To bridge these gaps, we introduce prompt engineering, RAG, and fine-tuning techniques to prepare the student for domain-specific challenges.
Prompt engineering acts as a guide, providing instructions for tailored responses. It's like giving the student a script to follow, ensuring a professional tone in their answers while maintaining their existing knowledge.
RAG, on the other hand, equips the student with a specialized textbook for an open-book exam. This allows them to access real-time information to enhance their responses, ensuring accuracy and credibility.
Finally, fine-tuning involves a deep dive into the textbook, preparing the student for a closed-book exam where they must rely solely on their internalized knowledge. While this method ensures precise answers, there may be limitations in providing references.
For a quick start, prompt engineering is the way to go. As you progress, integrate RAG for dynamic information retrieval, and when ready, invest in fine-tuning with a diverse dataset for optimal performance.

 Twitter
Twitter Youtube
Youtube

